


Scaling Healthcare Tech: How We Migrated from Aptible to Google Kubernetes Engine



Key Takeaways
- Virta Health migrated from Aptible to Google Kubernetes Engine to gain greater flexibility, finer access control, and access to Google Cloud managed services.
- A single shared Helm chart with per-application values standardized deployments, simplified developer workflows, and made infrastructure improvements available across all services at once.
- The cutover used Envoy and Honeycomb to shift traffic gradually from Aptible to GCP, allowing careful monitoring, rollback, and validation before reaching 100% traffic on the new platform.
- Virta Health combines healthcare compliance with modern cloud infrastructure on GCP, making it a strong option for teams that want scalable, interoperable, and reliable digital care systems.
As a software engineer on Virta’s infrastructure team, my work focuses on enabling my teammates to do the highest impact work as efficiently as possible. The ever-changing needs of a rapidly scaling tech company means that a significant portion of this work involves assessing and replacing our tools and services to better meet those needs.
In 2015, we launched the technical portion of our continuous remote care platform using a managed, HIPAA compliant container orchestration platform called Aptible. At the time, this was the right choice for a small healthcare startup like Virta. Aptible came with built-in compliance and abstracted away a lot of the infrastructure decisions that we didn’t need to worry about at that point. Aptible also provided an easy-to-use interface so that our developers could spend their time building our product instead of worrying about the nitty-gritty of how it was run. However, as our small startup grew into an established business with increasing technical complexity, we started to outgrow the usefulness provided by the simplicity of Aptible. By the time I joined Virta in June of 2020, we had decided to migrate our workloads over to Google Cloud Platform’s (GCP) managed Google Kubernetes Engine (GKE) service.
There were several main motivations for this switch from Aptible to GKE. In the early days, Aptible’s managed platform was great for taking complexity off our plate. But as we grew and our systems became more complex, we had an increasing need to manage this complexity ourselves. Moving to GCP gave us:
- Greater Optionality: Flexibility and control within our networking, scaling, and tooling decisions.
- Detailed Permissioning: Fine-grained ability to permission and grant access to various workflows while restricting others, which is crucial as our engineering team grows.
- Managed Tools: Access to industry-leading managed tools such as Cloud Functions, Big Query, and the Cloud Healthcare API.
Our primary goal was to set up new systems that could successfully deploy and run all of our workloads, while minimizing the burden of having to learn a new system for our feature developers. To successfully achieve our goals, we first needed to design and build a new system that was similarly abstracted to the old system. Once built, we had to make sure this system was fully tested and validated by stakeholders. Finally, once everything was up and running, we needed a safe, straightforward, and well-instrumented method of switching traffic over to the new system.
We decided to use a templating tool called Helm to deploy our applications as Kubernetes objects, which is helpful for coding Kubernetes objects consistently. The setup effectively comprises three parts:
- A set of templates, which define the Kubernetes objects that will be created, such as deployments, services, and policies.
- A values.yaml file, which is fed to the template and defines any application-specific values, such as external endpoints, environment variables, and replica counts.
- A deployment invocation combining the two, which can also take any additional configuration value information that you want to specify at the time of deployment, such as cluster information or the application image to use.
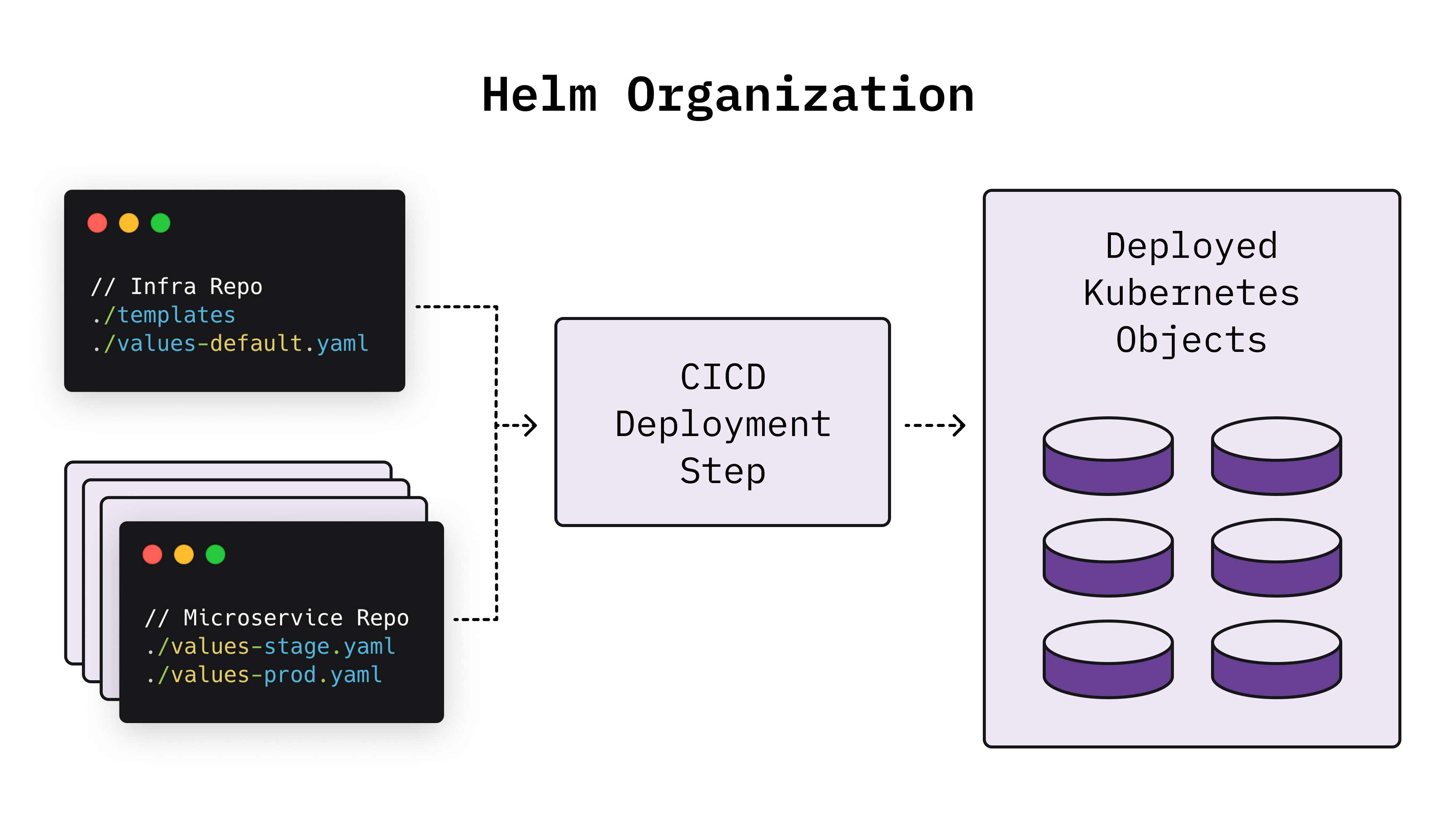
For our applications, we decided to use a single Helm chart (the template portion) for all applications, and rely entirely on the values.yaml file to define anything application-specific. This was helpful because we wanted to abstract away as many Kubernetes considerations as possible from developers, who we don’t expect to have an in-depth understanding of Kubernetes. The values.yaml file provides them with a simple interface containing all of the information specific to their application’s implementation. This design also nets us some security benefits, since only a small group of infrastructure engineers has direct code access to the Helm chart and thus the ability to create and modify objects in our infrastructure. Finally, a single Helm chart also enables us to roll out any infrastructure changes quickly, as we need to make the changes in only one place.
I initially found this project quite daunting. Based on my prior experiences, I thought we’d have to use individual charts for separate applications, and we had dozens of very different microservices. However, once I looked more closely, it became clear that most applications don’t need a particularly unique combination of Kubernetes objects.
Our Helm chart has a baseline of 3 key features:
- A deployment, with the option to specify multiple deployments for applications with related helper processes.
- A service and VirtualService, to provide access to the application (we use Istio for our networking).
- A service account, which we use to enable workload identity within the GCP ecosystem.
There are many other configurations within our Helm chart, but they are not critical for the purposes of this discussion.

As more complex use-cases arise for specific applications, the solutions are generally applicable to all applications. Thus we can easily iterate and expand on the chart in order to roll out broad improvements. For example, we realized that the Kubernetes default deployment upgrade strategy was resulting in an unacceptable reduction in capacity for a key service during deployments, so we added a stricter pod disruption budget, which ensures that we always have adequate replicas of that service. Because we used a single Helm chart, we automatically gained that stricter pod disruption budget for every app, with smart defaults, which protects us from similar issues in the future.
Once we had the Helm chart put together, with initial values.yaml files added wherever necessary, we added steps to our CICD pipelines to deploy each application to our GKE stage & production clusters, in addition to our current working setup. We soon had relatively functional copies of our full system running in GKE. I say “relatively” for a reason — up to this point the infrastructure team had been doing most of the work. Like many infra teams, we don’t have particularly deep knowledge of the inner workings of our applications. We tend to rely on our feature teams for the various idiosyncrasies of configuration, which don’t always fully make it into documentation.
While our whole engineering team was aware of this migration, we didn’t bring feature teams in until we had a complete replica in stage and needed their help with the fine tuning. To get started, we formed a working group, with a representative from each feature team, and held weekly training & feedback sessions. These sessions provided an important two-way flow of information designed to make the migration easier for everyone.
In terms of training, it was important for feature engineers to become familiar with the new system. While we did a good job abstracting the Kubernetes-specific details of how apps were constructed, developers still had to learn to interact with the system for testing and troubleshooting. This included familiarization with the Google Cloud console and CLI, as well as understanding how various concepts and functions in Aptible mapped to an equivalent in GCP. Developing these skills before the migration would be crucial to ensure a smooth transition and minimal disruption to developer experience.
In terms of feedback, as infrastructure engineers, we didn’t have the experience working with the apps necessary to effectively test and debug the many services. This deep knowledge from the feature engineers was helpful to understand what to test, as there are many specific workflows that had grown beyond what was effectively covered in documentation and automated testing. With the help of the feature teams, we were able to identify problems in these workflows that we wouldn’t have even known to check. Once problems were identified, the feature team engineers were better able to suggest solutions. For example, if a certain part of a web page is not loading properly, then it’s likely from a connectivity issue to another microservice.
Over the course of a few weeks, our working group hammered the stage and production GKE clusters into fully functional and tested states that ran in parallel with the old system. Then came the cutover. We were adamant that our cutover process be gradual, reversible, and well-instrumented to provide thorough telemetry. As a healthcare company, it’s critical that we are meticulous when making changes to user-facing workflows, as our users are both patients and providers. Having our applications go down puts patient care, and thus safety, at risk.
To achieve our cutover requirements, we decided to put an Envoy Proxy in front of our main external endpoints. Envoy’s easy integration with Honeycomb (our observability tool) provided us with rich telemetry data about the traffic going to our systems. Envoy also allowed us to set simple routing rules for determining the percentage of random traffic to send to one system or another. Finally, Envoy also had the capability to change those rules very quickly, with a single CLI command.

Initially we set up the Envoy Proxy as a no-op, with 100% of traffic routed to our old system by default. This allowed us to carefully review the data we were getting out of the proxy, and set up the dashboards and queries in Honeycomb that we needed to be prepared for the cutover. Once all that was in place, and after a final check of the functionality of the new system, we issued the command.
To start, we sent just 5% of our traffic to the GCP system for 15 minutes. We then flipped it back, and took the time to carefully analyze relevant metrics from that traffic such as 500 rate, latency differences, and any errors that popped up in Sentry (our exception handling tool). Once we were satisfied that nothing untoward had happened, we bumped it up to 15% of traffic. Then 25%, then 50%. After each traffic test, we’d return 100% of traffic back to Aptible to give us time to address any issues that arose. At first, there were occasional configuration defects or scaling issues that needed to be fixed, but after about 2 weeks of rigorous testing, we were confident in flipping 100% of traffic over to GCP. We hit this final project milestone with all traffic transitioned to GCP right before winter holidays. Even though we couldn’t be together in person, we managed to celebrate in true remote-first fashion, with Virta-sponsored Drizly delivery and a truly rewarding team Zoom celebration!
This is obviously not the end, nor the entirety, of our migration story. All of our data stored in Aptible had to be migrated to GCP. Other tools, such as RabbitMQ, required similarly careful migrations. The Envoy Proxy was hosted in Aptible, so that eventually had to be taken down. Then we had to tackle removing references and CICD steps pointing to Aptible, as well as deprecating any tools that were now irrelevant. Even before this work is wrapped up, we are already reaping the benefits from the migration.
For example, our RabbitMQ instance had been a point of failure in the past, and hosting it ourselves has allowed us to implement more detailed configuration. Now, we’ve been able to implement several reliability initiatives to strengthen these systems. After we took down the Envoy Proxy, we made a point to export the equivalent logs from Google Cloud Logging to Honeycomb so that we could maintain and build upon the improved insights into our traffic patterns.
More importantly, we had already been using some of Google’s managed services, and moving to GCP made that integration even easier. Google’s Identity-Aware Proxy is a key component of our authentication and authorization systems for internal applications. We are now working to leverage this identity platform for managed external authorization too. We increasingly use Cloud Functions to start taking advantage of serverless applications, and Pub/Sub as an alternative to RabbitMQ.
As a healthcare technology company, we are particularly excited about Cloud Healthcare API, and are continually moving more and more workloads into FHIR stores. We firmly believe in and support the FHIR standard as the future of interoperability. We adhere to a principle of developing around FHIR rather than manipulating our data post-hoc to fit. Cloud Healthcare API provides us a functional, compliant, and validated FHIR store out of the box, and was thus a key motivating factor for our migration. Overall, we are immensely pleased with the service gains we’ve acquired from moving to GCP.
What’s next? We are now planning further infrastructure investments made possible by running on GCP. These include implementing Anthos Service Mesh to improve and simplify our networking, enabling Autopilot to optimize our cluster scaling, and using Cloud Run to expand our serverless implementations. Personally, I’m most excited to implement even more sophisticated scaling policies so that Virta’s technology can continue to scale at the speed of a high growth company.
This blog is intended for informational purposes only and is not meant to be a substitute for professional medical advice, diagnosis, or treatment. Always seek the advice of your physician or other qualified health provider with any questions you may have regarding a medical condition or any advice relating to your health. View full disclaimer
Are you living with type 2 diabetes, prediabetes, or unwanted weight?
